3
Hands-on Introduction to MOA
In this chapter, we are going to start using MOA, learn its basics, and run a simple example comparing two classifiers. If you have some background in data mining for the nonstreaming setting, this quick start should let you explore other options, such as clustering and frequent pattern mining. Otherwise, it is probably best to continue with part II which covers these techniques.
3.1 Getting Started
First, we need to download the lastest release of MOA from
https://moa.cms.waikato.ac.nz
. It is a compressed zip file that contains the
moa.jar
file, an executable Java jar file that can be used either as a Java
application or from the command line. The release also contains the jar file
sizeofag.jar
, which is used to measure the memory used running the experiments. The scripts
bin\moa.bat
in Windows and
bin/moa.sh
in Linux and Mac are the easy way to start the graphical user interface of MOA (
figure 3.1
).

Figure 3.1
MOA graphical user interface.
Click Configure to set up a task; when ready to launch a task, click Run . Several tasks can be run concurrently. Click on different tasks in the list and control them using the buttons underneath. If textual output from a task is available, it will be displayed in the center of the GUI, and can be saved to disk.
Note that the command line text box displayed at the top of the window represents textual commands that can be used to run tasks on the command line. The text can be selected, then copied onto the clipboard. At the bottom of the GUI there is a graphical display of the results. It is possible to compare the results of two different tasks: the current task is displayed in red, and the previously selected task is in blue.
As an example, let us compare two different classifiers, a Naive Bayes and a decision tree, using prequential evaluation on 1,000,000 instances generated by the default
RandomTreeGenerator
stream generator (
figure 3.2
):
EvaluatePrequential -i 1000000 -f 10000 -l bayes.NaiveBayes
EvaluatePrequential -i 1000000 -f 10000 -l trees.HoeffdingTree
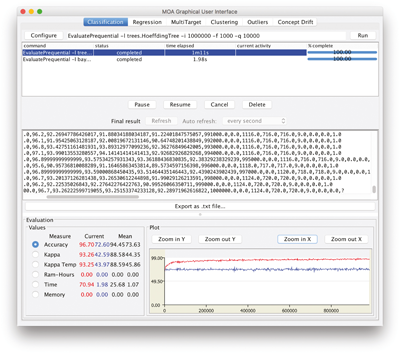
Figure 3.2
MOA GUI running two different tasks.
Remember that the prequential evaluation is an online evaluation technique distinct from the standard cross-validation used in the batch setting. Each time a new instance arrives, it is first used to test, then to train.
You can use streams from ARFF files, a convenient data format defined by the WEKA project. Sample ARFF datasets are available from https://moa.cms.waikato.ac.nz .
EvaluatePrequential -s (ArffFileStream -f elec.arff)
Also, you can generate streams with concept drift, joining several different streams. For example, the SEA concepts dataset is generated joining four different streams with a different SEA concept in each one:
3.2 The Graphical User Interface for Classification
We start by comparing the accuracy of two classifiers.
Exercise 3.1
Compare the accuracies of the Hoeffding tree and the Naive Bayes classifiers, for a
RandomTreeGenerator
stream of 1,000,000 instances, using interleaved test-then-train evaluation. Use a sample frequency of 10,000 instances to output the evaluation results every 10,000 instances.
We configure and run the following tasks:
EvaluateInterleavedTestThenTrain -l bayes.NaiveBayes
-i 1000000 -f 10000
EvaluateInterleavedTestThenTrain -l trees.HoeffdingTree
-i 1000000 -f 10000
The results are shown in figure 3.3 .

Figure 3.3
Exercise 3.1, comparing the Naive Bayes Classifier and the Hoeffding tree.
Exercise 3.2 Compare and discuss the accuracy for the stream in the previous example using three different evaluations with a Hoeffding tree:
- Periodic holdout with 1,000 instances for testing
- Interleaved test-then-train
- Prequential with a sliding window of 1,000 instances
The tasks needed for this example are the following:
- Periodic holdout with 1,000 instances for testing:
EvaluatePeriodicHeldOutTest -n 1000 -i 1000000 -f 10000
- Interleaved test-then-train:
EvaluateInterleavedTestThenTrain -l trees.HoeffdingTree
-i 1000000 -f 10000
- Prequential with a sliding window of 1,000 instances:
EvaluatePrequential -l trees.HoeffdingTree -i 1000000 -f 10000
The comparison between the first two is shown in figure 3.4 .
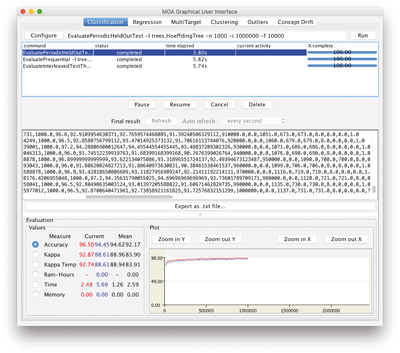
Figure 3.4
Exercise 3.2, comparing three different evaluation methods on the same classifier.
3.2.1 Drift Stream Generators
MOA streams are built using generators, reading ARFF files, joining several streams, or filtering streams. MOA stream generators allow us to simulate potentially infinite sequences of data.
It is possible to build streams that exhibit concept drift, or concept change over time. Two examples are the rotating hyperplane and the random RBF generator. The rate of change in these streams is determined by a parameter, and their operation will be explained in chapter 12.
We can also introduce concept drift or change by joining several streams. In MOA this is done by building a weighted combination of two pure distributions that characterizes the target concepts before and after the change. MOA uses the sigmoid function as an elegant and practical solution to define the probability that each new instance of the stream belongs to the new concept after the drift. The sigmoid function introduces a gradual, smooth transition whose duration is controlled with two parameters: p , the position where the change occurs, and the length w of the transition, as can be seen in figure 3.5 .

Figure 3.5
A sigmoid function
f
(
t
) = 1/(1 +
e
−4(
t
−
p
)
/w
).
An example is:
ConceptDriftStream -s (generators.AgrawalGenerator -f 7)
-d (generators.AgrawalGenerator -f 2) -w 1000000 -p 900000
where the parameters of
ConceptDriftStream
are:
-
-s: Initial stream generator -
-d: Generator of the stream after drift or change -
-p: Central position of the change -
-w: Width of the change period
Exercise 3.3
Compare the accuracy of the Hoeffding tree with the Naive Bayes classifier, for a
RandomRBFGenerator
stream of 1,000,000 instances with speed change of 0.001 using interleaved test-then-train evaluation.
The tasks needed for this example are:
EvaluateInterleavedTestThenTrain -l bayes.NaiveBayes
-s (generators.RandomRBFGeneratorDrift -s 0.001)
-i 1000000 -f 10000
EvaluateInterleavedTestThenTrain -l trees.HoeffdingTree
-s (generators.RandomRBFGeneratorDrift -s 0.001)
-i 1000000 -f 10000
The comparison between the two classifiers is shown in figure 3.6 .
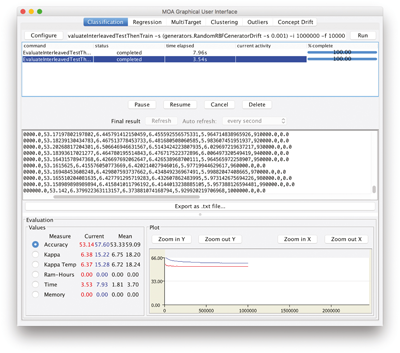
Figure 3.6
Exercise 3.3, comparing the Hoeffding tree and Naive Bayes classifiers on a nonstationary stream.
Exercise 3.4 Compare the accuracy for the stream of the previous exercise using three different classifiers:
- Hoeffding tree with majority class at the leaves
- Hoeffding adaptive tree
-
ADWIN bagging (
OzaBagAdwin) on ten Hoeffding trees
The tasks needed for this example are:
EvaluateInterleavedTestThenTrain -l (trees.HoeffdingTree -l MC)
-s (generators.RandomRBFGeneratorDrift -s 0.001)
-i 1000000 -f 10000
EvaluateInterleavedTestThenTrain -l trees.HoeffdingAdaptiveTree
-s (generators.RandomRBFGeneratorDrift -s 0.001)
-i 1000000 -f 10000
EvaluateInterleavedTestThenTrain -l meta.OzaBagAdwin
-s (generators.RandomRBFGeneratorDrift -s 0.001)
-i 1000000 -f 10000
The comparison of these three classifiers is shown in figure 3.7 . We observe that the two adaptive classifiers perform much better than the standard Hoeffding tree, since the data stream is evolving and changing.

Figure 3.7
Exercise 3.4, comparing three different classifiers.
3.3 Using the Command Line
An easy way to use the command line is to copy and paste the text in the Configure line of the GUI. For example, suppose we want to execute the task
EvaluatePrequential -l trees.HoeffdingTree -i 1000000 -w 10000
from the command line. We can simply write
java -cp moa.jar -javaagent:sizeofag.jar moa.DoTask
"EvaluatePrequential -l trees.HoeffdingTree -i 1000000 -w 10000"
Note that some parameters are missing, so default values will be used. We explain this line in the following paragraphs.
The class
moa.DoTask
is the main one for running tasks on the command line. It will accept the name of a task followed by any appropriate parameters. The first task used is the
LearnModel
task. The
-l
parameter specifies the learner, in this case the
HoeffdingTree
class. The
-s
parameter specifies the stream to learn from, in this case
generators.WaveformGenerator
, which is a data stream generator that produces a three-class learning problem of identifying three types of waveform. The
-m
option specifies the maximum number of examples to train the learner with, in this case 1,000,000 examples. The
-O
option specifies a file to output the resulting model to:
java -cp moa.jar -javaagent:sizeofag.jar moa.DoTask
LearnModel -l trees.HoeffdingTree
-s generators.WaveformGenerator -m 1000000 -O model1.moa
This will create a file named
model1.moa
that contains a decision tree model that was induced during training.
The next example will evaluate the model to see how accurate it is on a set of examples that are generated using a different random seed. The
EvaluateModel
task is given the parameters needed to load the model produced in the previous step, generate a new waveform stream with random seed 2, and test on 1,000,000 examples:
java -cp moa.jar -javaagent:sizeofag.jar moa.DoTask
"EvaluateModel -m file:model1.moa
-s (generators.WaveformGenerator -i 2) -i 1000000"
Note that we are nesting parameters using brackets. Quotes have been added around the description of the task, otherwise the operating system might be confused about the meaning of the brackets.
After evaluation the following statistics are displayed:
classified instances = 1,000,000
classifications correct (percent) = 84.474
Kappa Statistic (percent) = 76.711
Note that the two steps above can be rolled into one, avoiding the need to create an external file, as follows:
java -cp moa.jar -javaagent:sizeofag.jar moa.DoTask
"EvaluateModel -m (LearnModel -l trees.HoeffdingTree
-s generators.WaveformGenerator -m 1000000)
-s (generators.WaveformGenerator -i 2) -i 1000000"
The task
EvaluatePeriodicHeldOutTest
will train a model while taking snapshots of performance using a holdout test set at periodic intervals. The following command creates a
comma-separated value
(CSV) file, training the
HoeffdingTree
classifier on the
WaveformGenerator
data, using the first 100,000 examples for testing, training on a total of 100,000,000 examples, and testing every 1,000,000 examples:
java -cp moa.jar -javaagent:sizeofag.jar moa.DoTask
"EvaluatePeriodicHeldOutTest -l trees.HoeffdingTree
-s generators.WaveformGenerator
-n 100000 -i 10000000 -f 1000000" > dsresult.csv
These are examples of how we can use MOA from the command line. In part II of the book we discuss the classifiers that appear here. In part III we explain the generators used here, and see how to use the MOA API from source code written in Java.