11
Introduction to MOA and Its Ecosystem
M assive O nline A nalysis (MOA) is an open-source software framework that allows users to build and run ML and data mining experiments on evolving data streams. It is being developed at the University of Waikato in New Zealand and named after the large, extinct, flightless moa bird that used to live only in New Zealand.
The distinctive feature of MOA is that it can learn and mine from large datasets or streams by performing only one pass over the data, with a small time per data item. As it scans the data, it only stores summaries and statistics rather than the instances themselves, so memory use is usually small too.
MOA is written in Java and distributed under the terms of the GNU General Public License. It includes a set of learners, stream generators, and evaluators that can be used from the graphical user interface (GUI), the command-line interface (CLI), and the Java API. Advantages of being Java-based are the portability and the strong and well-developed support libraries. Use of the language is widespread, and features such as automatic garbage collection help reduce programming burden and errors. MOA runs on any platform with an appropriate Java virtual machine, such as Linux, Mac, Windows, and Android.
One intended design goal of MOA is to be easy to use and simple to extend.
There are several open-source software libraries related to MOA. Some of them, such as ADAMS, MEKA, and OpenML, use MOA to perform data stream analytics inside their systems. StreamDM contains an implementation in C++ of some of the most popular methods in MOA, and Apache SAMOA is a new platform that performs stream mining in a distributed environment using Hadoop hardware.
In this part of the book, we show how to use the GUI, the CLI, and the Java API, and how to master MOA algorithms, generators, and evaluators.
In this chapter, we first discuss briefly the architecture of MOA, and how to install the software. After that we look at recent developments in MOA and the extensions available in MOA, and finally we present some of the open-source frameworks that can be used with MOA, or as an alternative to it. The intention is not to make readers proficient in all these other packages, but to make them aware of their possibilities.
11.1 MOA Architecture
MOA is built around the idea of the task . All experiments run in MOA are defined as tasks. There are simple tasks, such as writing streams to files or computing the speed of a stream, but the most important tasks are the evaluation tasks. For example, in classification, there are two main types of evaluation methods, described in section 6.1: holdout and prequential.
MOA contains methods for classification, regression, clustering, outlier detection, recommendation, and frequent pattern mining. Tasks are usually composed of stream sources, learners, and the parameters of the evaluation, such as number of instances to use, periodicity of the output result, and name of the file to output the predictions. Also, different task types require different evaluation strategies.
Tasks can be run from the GUI or from the CLI.
11.2 Installation
MOA is available from
https://moa.cms.waikato.ac.nz
, where the latest release can always be downloaded as a compressed zip file. The release contains a
moa.jar
file, an executable Java jar file that can be run as a Java application or called from the command line. It also contains the
sizeofag.jar
file, used to measure the memory used by experiments. The scripts
bin\moa.bat
in Windows and
bin/moa.sh
in Linux and Mac are the easiest way to start MOA’s GUI.
11.3 Recent Developments in MOA
Some of the recent developments in MOA, not covered in detail in this book, are:
- Multitarget learning: A tab for multitarget learning [ 91 , 188 , 232 ], where the goal is to predict several related target attributes simultaneously. Examples of multitarget learning are the prediction of temperatures in the same building, traces in the same road network, or stock prices.
- Outlier detection : A tab for detection of distance-based outliers [ 20 , 120 ]. This tab uses the most widely employed criteria for determining whether an element is an outlier, based on the number of neighboring elements within a fixed distance, against a fixed threshold.
-
Recommender system
: MOA has a task to use online recommender algorithms. The
EvaluateOnlineRecommendertask in MOA takes a rating predictor and a dataset (each training instance being a [user, item, rating] triplet) and evaluates how well the model predicts the ratings, given the user and item, as more and more instances are processed. This is similar to the online scenario of a recommender system, where new ratings of items by users arrive constantly, and the system has to make predictions of unrated items for the user in order to know which ones to recommend. There are two online recommender algorithms available:BaselinePredictorandBRISMFPredictor. The first is a very simple rating predictor, and the second implements a factorization algorithm described in [ 234 ].
11.4 Extensions to MOA
The following useful extensions to MOA are available from its website:
- IBLStreams: IBLStreams [ 225 ], described in section 8.4, is an instance-based learning algorithm for classification and regression problems on data streams.
- MOA-IncMine: IncMine, proposed in [ 66 ] and described in section 10.3.4, computes frequent closed itemsets from evolving data streams. The implementation in MOA is described in [ 202 ] and uses the implementation of the CHARM batch miner from [ 106 ].
- MOA-AdaGraphMiner: AdaGraphMiner [ 35 ] (see section 10.4) is a framework for mining frequent subgraphs in time-varying streams. It contains three new methods for mining frequent closed subgraphs. All methods work on coresets of closed subgraphs, compressed representations of graph sets, and maintain these sets in a batch-incremental manner, but use different approaches to address potential concept drift.
- MOA-Moment: Moment [ 70 ] is a closed frequent itemset miner over a stream sliding window. This version was implemented by M. Jarka ( www.admire-project.eu ).
- MOA-TweetReader: This extension reads and converts tweets from the Twitter Streaming API to MOA instances, to facilitate streaming analysis of tweets.
- Classifiers & DDMs: This extension provides several published ensemble classifiers (DWM, RCD, Learn++.NSE, EB), concept drift detectors (ECDD, PHT, Paired Learners), and artificial datasets (Sine and Mixed).
- MODL split criterion and GK class summary: This new split criterion for numeric attributes is based on the MODL approach [ 48 ]. The GK class summary is based on Greenwald and Khanna’s quantile summary (see section 6.4.3) but in this version class counts are included in each tuple in the summary.
- Incrementally Optimized Very Fast Decision Tree (iOVFDT): A new extension of the Hoeffding tree (section 6.3.2) proposed in [ 132 ].
- Anytime Nearest Neighbor : Implementation by Liu and Bell of the anytime classifier presented in [ 227 ].
- Social Adaptive Ensemble 2 (SAE2) : Social-based algorithms, Scale-Free Network Classifier (SFNClassifier) [ 25 , 126 ], and the Social Network Clusterer Stream (SNCStream) [ 26 ].
- Framework for Sentiment Analysis of a Stream of Texts : This project’s goal was to build an online, real-time system able to analyze an incoming stream of text and visualize its main characteristics using a minimal desktop application [ 18 ].
- MOAReduction : An extension for MOA that allows users to perform data reduction techniques on streams without drift. It includes several reduction methods for different tasks, such as discretization, instance selection, and feature selection, as presented in [ 205 ].
- MOA for Android : Contains software to make MOA usable as part of an Android application.
11.5 ADAMS
WEKA and MOA are powerful tools to perform data mining analysis tasks. Usually, in real applications and professional settings, the data mining processes are complex and consist of several steps. These steps can be seen as a workflow. Instead of implementing a program in Java, a professional data miner will build a solution using a workflow, so that it will be much easier to understand and maintain for nonprogrammer users. The Advanced Data mining And Machine learning System (ADAMS) [ 213 , 214 ] is a flexible workflow engine aimed at quickly building and maintaining real-world, complex workflows. It integrates data mining applications such as MOA, WEKA, and MEKA, support for the R language, image and video processing and feature generation capabilities, spreadsheet and database access, visualizations, GIS, web services, and fast prototyping of new functionalities using scripting languages (Groovy/Jython).
The core of ADAMS is the workflow engine, which follows the philosophy of less is more. Instead of letting the user place operators (or actors, in ADAMS terms) on a canvas and then manually connect inputs and outputs, ADAMS uses a treelike structure. This structure and the control actors define how the data flows in the workflow; no explicit connections are necessary. The treelike structure stems from the internal object representation and the nesting of subactors within actor handlers.
Figure 11.1 shows the ADAMS flow editor loaded with the adams-moa-classifier-evaluation flow. It uses the Kappa statistic and a decision stump, a decision tree with only one internal node. Figure 11.2 shows the result of running the workflow.
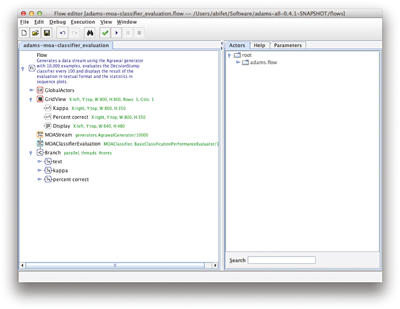
Figure 11.1
The ADAMS flow editor.
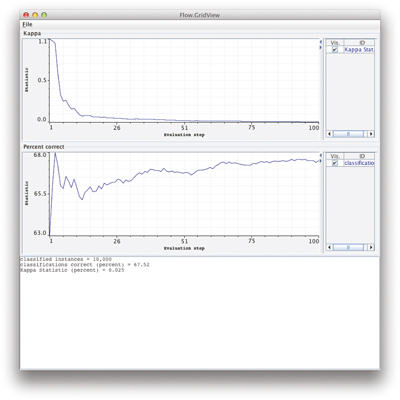
Figure 11.2
The ADAMS flow example.
ADAMS can also perform tweet analysis. Tweets and their associated metadata can be recorded using the public Twitter API, storing them for future replay. This tweet stream replay functionality allows the same experiment to be performed as often as required, using the same stream of tweets each time, and applying different filters (e.g., checking for metadata) and algorithms. Tweets with geotagging information can be displayed using the OpenStreetMap GIS functionality, allowing for visualization of geographical phenomena.
ADAMS is also able to process videos in near real time, with frames being obtained at specific intervals. Apart from tracking objects, it is also possible to use the image processing and feature generation functionality to generate input for ML platforms such as MOA or WEKA.
11.6 MEKA
MEKA [ 212 ] is an open-source project started at the University of Waikato to perform and evaluate multi-label classification. It uses the so-called problem transformation methods to make WEKA single-label (binary or multiclass) methods available as base classifiers for multi-label classification; see Section 6.7.
MEKA contains all the basic problem transformation methods, advanced methods including varieties of classifier chains that have often been used as a benchmark in the recent multi-label literature, and also algorithm adaptations such as multi-label neural networks and deep neural networks. It includes two strategies for automatic threshold calibration, and a variety of evaluation metrics from the literature. MEKA is easy to use from either the CLI or the GUI ( figure 11.3 ). Thus no programming is required to parameterize, run, and evaluate classifiers, making it suitable for practitioners unfamiliar with Java. However, it is straightforward to extend MEKA with new classifiers and integrate it into other frameworks. Those familiar with WEKA will have almost no learning curve—much of WEKA’s documentation and modus operandi is directly applicable. Any new MEKA classifier can also be combined within any of MEKA’s existing ensemble schemes and any WEKA base classifier without writing extra code, and may be compared easily with benchmark and state-of-the-art methods. MEKA also supports semisupervised and streaming classification in the multi-label context, as discussed in section 6.7.

Figure 11.3
The MEKA GUI.
11.7 OpenML
OpenML [ 238 , 239 ] is an online platform where scientists can automatically log and share machine learning datasets, code, and experiments, organize them online, and build directly on the work of others. It helps automate many tedious aspects of research, it is readily integrated into several ML tools, and it offers easy-to-use APIs. It also enables large-scale and real-time collaboration, allowing researchers to share their very latest results, while keeping track of their impact and reuse. The combined and linked results provide a wealth of information to speed up research, assist people while they analyze data, or automate the experiments altogether.
OpenML features an extensive REST API to search, download, and upload datasets, tasks, flows, and runs. Moreover, programming APIs are offered in Java, R, and Python to allow easy integration into existing software tools. Using these APIs, OpenML is already integrated into MOA, as shown in figure 11.4 . In addition, R and Python libraries are provided to search and download datasets and tasks, and upload the results of ML experiments in just a few lines of code.
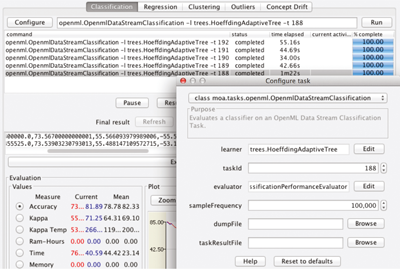
Figure 11.4
Integration of OpenML with MOA.
11.8 StreamDM
StreamDM-C++ [ 43 ] is an open-source project started at the Huawei Noah’s Ark Lab. It implements Hoeffding adaptive trees (section 6.3.5) for data streams in C++ and has been used extensively at Huawei. Hoeffding adaptive trees adapt to changes in streams, a huge advantage since standard decision trees are built using a snapshot of data and cannot evolve over time.
StreamDM for Spark Streaming [ 39 ] is an open-source project for mining big data streams using Spark Streaming [ 253 ], an extension of the core Spark API that enables scalable stream processing of data streams.
11.9 Streams
The
streams
[
46
] framework is a Java implementation of a simple stream processing environment. It aims at providing a clean and easy-to-use Java-based platform to process streaming data. The core module of the streams library is a thin API layer of interfaces and classes that reflect a high-level view of streaming processes. This API serves as a basis for implementing custom processors and providing services with the streams library.
The
stream-analysis
modules of the
streams
library provide implementations for online methods for analysis, such as different approximative counting algorithms and computation of online statistics (e.g., quantile summaries). As
streams
incorporates MOA, the methods from MOA are available inside the framework.
11.10 Apache SAMOA
Apache Scalable Advanced Massive Online Analysis ( SAMOA ) [ 181 ] is a framework that provides distributed ML for big data streams, with an interface to plug in different stream processing platforms that run in the Hadoop ecosystem.
SAMOA can be used in two different modes: it can be used as a running platform to which new algorithms can be added, or developers can implement their own algorithms and run them within their own production system. Another feature of SAMOA is the stream processing platform abstraction, where developers can also add new platforms by using the available API. With this separation of roles, the SAMOA project is divided into the SAMOA API layer and the DSPE-adapter layer. The SAMOA API layer allows developers to develop for SAMOA without worrying about which distributed stream processing engine (SPE) will be used. When new SPEs are released or there is interest in integrating with another platform, a new DSPE-adapter layer module can be added. Currently, SAMOA supports four SPEs that are currently state-of-the-art: Apache Flink, Storm, Samza, and Apex.
The SAMOA modular components are processor , stream , content event , topology , and task .
- A processor in SAMOA is a unit-of-computation element that executes some part of the algorithm on a specific SPE . Processors contain the actual logic of the algorithms. Processing Items (PIs) are the different internal, concrete implementations of processors for each SPE.
The SPE-adapter layer handles the instantiation of PIs. There are two types of PI, an entrance PI and a normal PI . An entrance PI converts data from an external source into instances, or independently generates instances. Then it sends the instances to the destination PI via the corresponding stream using the correct type of content event. A normal PI consumes content events from an incoming stream, processes the content events, and may send the same content events or new content events to outgoing streams. Developers can specify the parallelism hint , which is the number of runtime PIs during SAMOA execution, as shown in figure 11.5 . A runtime PI is an actual PI that is created by the underlying SPE during execution. SAMOA dynamically instantiates the concrete class implementation of the PI based on the underlying SPE.
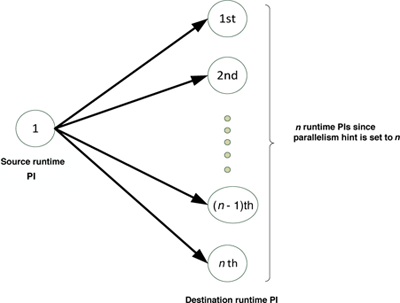
Figure 11.5
Parallelism hint in
SAMOA
.
A PI uses composition to contain its corresponding processor and streams. A processor is reusable, which allows developers to use the same implementation of processors in more than one ML algorithm implementation. The separation between PIs and processors allows developers to focus on developing their algorithms without worrying about the SPE-specific implementation of PIs.
- A stream is a connection from a PI into its corresponding destination PIs. Developers view streams as connectors between PIs and as mediums to send content events between PIs. A content event wraps the data transmitted from a PI to another via a stream. Moreover, in a way similar to processors, content events are reusable. Developers can use a content event in more than one algorithm.
- A source PI is a PI that sends content events through a stream. A destination PI is a PI that receives content events via a stream. Developers instantiate a stream by associating it with exactly one source PI. When destination PIs want to connect to a stream, they need to specify the grouping mechanism, which determines how the stream routes the transported content events.
- A topology is a collection of connected processing items and streams. It represents a network of components that process incoming data streams. A distributed streaming algorithm implemented on top of SAMOA corresponds to a topology.
- A task is an ML-related activity such as performing a specific evaluation for a classifier. An example of a task is a prequential evaluation task, that is, a task that uses each instance for testing the model performance and then uses the same instance to train the model using specific algorithms. A task also corresponds to a topology in SAMOA .
Platform users esentially call SAMOA tasks. They specify what kind of task they want to perform, and SAMOA automatically constructs a topology based on the task. Next, platform users need to identify the SPE cluster that is available for deployment and configure SAMOA to execute on that cluster. Once the configuration is correct, SAMOA deploys the topology seamlessly into the configured cluster, and platform users can observe the execution results through dedicated log files of the execution.
The ML-adapter layer in SAMOA consists of classes that wrap ML algorithm implementations from other ML frameworks. Currently SAMOA has a wrapper class for MOA algorithms or learners, which means SAMOA can easily use MOA learners to perform some tasks. SAMOA does not change the underlying implementation of the MOA learners, so the learners still execute in a sequential manner on top of the SAMOA underlying SPE.
Developers design and implement distributed streaming ML algorithms with the abstraction of processors, content events, streams, and processing items. Using these modular components, they have flexibility in implementing new algorithms by reusing existing processors and content events, or writing new ones from scratch. They have also flexibility in reusing existing algorithms and learners from existing ML frameworks using the ML-adapter layer.
Developers can also implement tasks with the same abstractions. Since processors and content events are reusable; the topologies and their corresponding algorithms are also reusable. This means they also have flexibility in implementing new tasks by reusing existing algorithms and components, or by writing new algorithms and components from scratch.
Currently, SAMOA contains these algorithms:
- Vertical Hoeffding tree [ 149 ]: A vertical parallelism approach partitions instances in terms of attributes for parallel processing. Decision tree inducers with vertical parallelism process the partitioned instances (which consist of subsets of attributes) to compute splitting criteria in parallel. For example, if we have instances with 100 attributes and we partition the instances into 5 portions, we will have 20 attributes per portion. In each portion, the algorithm processes the 20 attributes in parallel to determine the locally best attribute to split, and combines the parallel computation results to determine the globally best attribute to split and grow the tree.
- AMRules [ 241 ]: SAMOA uses a hybrid of vertical and horizontal parallelism to distribute AMRules on a cluster. The decision rules built by AMRules are comprehensible models, where the antecedent of a rule is a conjunction of conditions on the attribute values, and the consequent is a linear combination of the attributes.
- Adaptive bagging: This is an easy method to parallelize. Each bagging replica is given to a different processor.
- Distributed clustering: Clustering in SAMOA has two levels: a first level that performs clustering on the split data, and a second level that performs a meta-clustering with the microclusters of the output of the first level.